Introduction to Datapipe
Datapipe, an open-source Python library, offers a solution for real-time, incremental ETL (Extract, Transform, Load) processes with a unique feature of record-level dependency tracking. Designed for crafting data processing pipelines, Datapipe excels in tracking dependencies for each record, ensuring that only modified data is processed, which significantly enhances data handling efficiency.
The primary Datapipe repository is hosted on GitHub at https://github.com/epoch8/datapipe. A repository dedicated to practical examples can be found at https://github.com/epoch8/datapipe-examples/.
This documentation is beneficial for those familiar with Python 3.8 or later. Knowledge of Sqlalchemy 1.4 or 2.0 is also recommended for a comprehensive understanding of Datapipe's functionalities.
We also recommend using Poetry (https://python-poetry.org/) for dependency management.
Строительные блоки в datapipe
Предметом описания в Datapipe является граф (мы называем его Pipeline)
преобразования данных.
Datapipe описывает его как последовательность преобразования данных (Table)
с помощью преобразований (Transform).
Таблицы
Datapipe
Типы преобразований в datapipe
Генерация данных из внешнего источника
- Парсинг YML фида и заполнение таблицы с данными
- Запрос внешнего АПИ для получения списка чего-то
Генерация идет батчами, объем заранее не известен.
Батч-трансформация данных 1-1 (без требования всех данных)
- Ресайз картинок
- Инференс модели машинного обучения
Батч-трансформация один-много, много-один на небольших батчах
- Распаковка свойств товара в отдельные записи: (product_id) → (product_id, property_id)
- Сборка данных о классифицированных ббоксах в одну запись: (image_id, bbox_id) → (image_id)
Глобальная (или около-глобальная трансформация)
Данные могут быть использованы несколько раз. Объем данных может не позволить загрузить в память целиком.
- Обучение модели машинного обучения на таблице
Типы ComputeStep
DatatableTransform
Принимает на вход список входных и выходных DataTable. Применяет к ним внешнюю
функцию.
Это поведение нельзя контролировать с точки зрения Changelist обработки.
Генерация и глобальная трансформация (обучение модели) относятся к такому типу обработки.
BatchTransform
Принимает в качестве аргументов функцию func, входные и выходные таблички для расчета трансформации.
Имеет выделенную функцию run_batch где внешняя система расчитала списки данных
на обработку и передала в функцию.
Подходит для Changelist обработки.
Батч-трансформации 1-1 и небольшие батчи 1-N, N-1 относятся к такому типу обработки.
Имеет magic injection:
- Если у функции
funcесть аргументds, то туда передатся используемыйDataStore. - Если у функции
funcесть аргументrun_config, то туда передатся используемый текущийRunConfig. - Если у функции
funcесть аргументidx, то туда передатся используемыйIndexDF-- текущие индексы обработки.
BatchGenerate
Принимает в качестве аргументов функцию-генератор func и выходные таблицы outputs. Требуется, если нужно определять какие-то первичные таблицы или периодически получать синхронизированные данные внешним способом (табличка в какой-то другой базе данных, файлы).
Имеет magic injection:
- Если у функции
funcесть аргументds, то туда передатся используемыйDataStore.
Case: model inference on images
Imagine we have two input tables:
modelsindexed bymodel_idimagesindexed byimage_id
We need to run transform model_infence which result in table
model_inference_for_image indexed by model_id,image_id.
Transform (individual tasks to run) is indexed by model_id,image_id.
Query is built by the following strategy:
- aggregate each input table by the intersection of it's keys and transform keys
- for each input aggregate:
- outer join transform table with input aggregate by intersection of keys
- select rows where update_ts > process_ts
- union all results
- select distinct rows
SQL query to find which tasks should be run looks like:
WITH models__update_ts AS (
SELECT model_id, update_ts
FROM models
),
images__update_ts AS (
SELECT image_id, update_ts
FROM images
)
SELECT
COALESCE(i.image_id, t.image_id) image_id,
COALESCE(i.model_id, t.model_id) model_id
FROM input__update_ts i
OUTER JOIN transform_meta t ON i.image_id = t.image_id AND i.model_id = t.model_id
WHERE i.update_ts > t.process_ts
Datapipe CLI
Datapipe provides datapipe CLI tool which can be useful for inspecting
pipeline, tables, and running steps.
datapipe CLI is build using click and provides several levels of commands
and subcommands each of which can have parameters. click parameters are
level-specific, i.e. global-level arguments should be specified at global level
only:
datapipe --debug run, but NOT datapipe run --debug
Global arguments
--pipeline
By default datapipe looks for a file app.py in working directory and looks
for app object of type DatapipeApp inside this file. --pipeline argument
allows user to provide location for DatapipeApp object.
Format: <module.import.path>:<symbol>
Format is similar to other systems, like uvicorn.
Example: datapipe --pipeline my_project.pipeline:app will try to import module
my_project.pipeline and will look for object app, it will expect this object
to be of type DatapipeApp.
--executor
Possible values:
SingleThreadExecutorRayExecutor
TODO add separate section which describes Executor
--debug, --debug-sql
--debug turns on debug logging in most places and shows internals of
datapipe processing.
--debug-sql additionally turns on logging for all SQL queries which might be
quite verbose, but provides insight on how datapipe interacts with database.
--trace-*
--trace-stdout--trace-jaeger--trace-jaeger-host HOST--trace-jaeger-port PORT--trace-gcp
This set of flags turns on different exporters for OpenTelemetry
db
create-all
datapipe db create-all is a handy shortcut for local development. It makes
datapipe to create all known SQL tables in a configured database.
lint
Runs checks on current state of database. Can detect and fix commong issues.
run
step
--nameis to provide a filter of steps with prefix matching of step name. Accepts a comma-separated list of prefixes. Example:datapipe step --name=my_step_name runordatapipe step --name=my_step_name,my_other_step_name run.--labelsis to provide a filter of steps according to its labels. Example:datapipe step --labels=my_label_name=my_label_value run.
run
Run steps. Could be used with --name and --labels options to filter steps.
list
Show steps in data pipeline. Could be used with --name and --labels options to filter steps.
--statusadds info about indexes to process.
reset-metadata
Mark data as unprocessed. Could be used with --name and --labels options to filter steps.
table
BatchTransform
BatchTransoform(
func: BatchTransformFunc,
inputs: List[PipelineInput],
outputs: List[TableOrName],
chunk_size: int = 1000,
kwargs: Optional[Dict[str, Any]] = None,
transform_keys: Optional[List[str]] = None,
labels: Optional[Labels] = None,
executor_config: Optional[ExecutorConfig] = None,
filters: Optional[LabelDict | Callable[[], LabelDict]] = None,
order_by: Optional[List[str]] = None,
order: Literal["asc", "desc"] = "asc",
)
Arguments
func
Function which is a body of transform, it receives the same number of
pd.DataFrame-s in the same order as specified in inputs
It should return a single pd.DataFrame if the output has one element or a
tuple of pd.DataFrame of the same length as output which will be interpreted
as corresponding to elements in output.
inputs
A list of input tables for a given transformation. Each element might be either:
- a string, this string will be interpreted as a name of
TablefromCatalog - an SQLAlchemy ORM table, this table will be added implicitly to
Catalogand used as an input - a qualifier
Requiredwith parameter either a string or an SQLAlchemy table, in this case same rules apply to the inner part and qualifierRequiredtells Datapipe that rows from this table must be present at calculation of transformations to compute
Example:
# ...
BatchTransform(
func=apply_detection_model,
inputs=[
# This is a table from Catalog.
# keys: <image_id>
"images",
# This is an SQLAlchemy table defined with declarative ORM.
# keys: <model_id>
DectionModel,
# This is a table from Catalog, which contains the identifier of current
# model, entries from DetectionModel will be filtered joining on `model_id`.
# keys: <model_id>
Required("current_model"),
],
# ...
)
# ...
outputs
chunk_size
kwargs
transform_keys
labels
executor_config
filters
order_by
order
TableStore
TBD
Database
TBD
Filedir
TBD
Redis
TBD
Elastic
TBD
Qdrant
TBD
Milvus
TBD
Lifecycle of a ComputeStep execution
As a computational graph node, transformation consists of:
input_dts- Input data tablesoutput_dts- Output data tables- Transformation logic
In order to run transformation, runtime performs actions with the following structure:
-
run_full/run_changelistget_full_process_ds/get_change_list_process_ids- Compute idx-es that require computation- For each
idxin batch:process_batch- Process batch in terms of DataTableprocess_batch_dts- Process batch with DataTables as input andpd.DataFrameas outputget_batch_input_dfs- Retreive batch data inpd.DataFrameformprocess_batch_df- Process batch in terms ofpd.DataFrame
- store results
-
store_batch_resultis called when batch was processed successfuly -
store_batch_erris called when there was an exception during batch processing
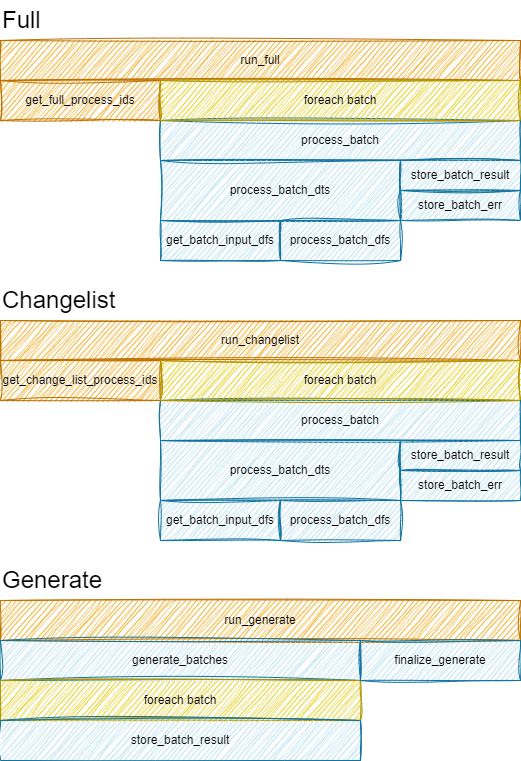
!! Note, lifecycle of generator is different
Using with SQLite
Python comes with some (at least 3.7.15) version of SQLite included.
Unfortunately for datapipe we need at least 3.39.0 version due to usage of
FULL OUTER JOIN in some queries. That's why we can't rely on Python embedded
sqlite module.
Installation
We configured sqlite extra in datapipe-core package, which installs
pysqlite3-binary and sqlalchemy-pysqlite3. With versions selected we can
guarantee that installed sqlite3 version is sufficient.
So specifying datapipe-core dependency with sqlite extra will provide
correct dependencies.
# pyproject.toml
datapipe-core = {version="^0.11.11", extras=["sqlite"]}
Gotchas
Alongside with pysqlite3-binary there's a package pysqlite3. In our
experience pysqlite3 package sometimes comes with old version of sqlite3,
please be aware.
Usage
In order to use sqlite3 as a storage for metadata you should specify dbconn with
"sqlite+pysqlite3://" driver:
dbconn = DBConn("sqlite+pysqlite3:///db.sqlite")
Extending datapipe cli
Entry point
Datapipe offers a way to add additional cli commands. It is achieved by utilizing Python entrypoints mechanism.
Datapipe looks for entrypoints with group name datapipe.cli and expects a
function with signature:
import click
def register_commands(cli: click.Group) -> None:
...
Context
Plugin can expect some information in click.Context:
-
ctx.obj["pipeline"]:datapipe.compute.DatapipeAppinstance of DatapipeApp with all necessary initialization steps performed -
ctx.obj["executor"]:datapipe.executor.Executorcontains an instance of Executor which will be used to perform computation
Example
To see example of extending datapipe cli see datapipe_app.cli:
https://github.com/epoch8/datapipe-app/blob/master/datapipe_app/cli.py
Developing TableStore
When you need it?
If you need Datapipe to read or write data to a specific database which is not supported out of the box, you will have to write custom TableStore implementation.
TableStore functionality overview
TBD
Testing
For testing standard TableStore implementation functionality there's a base set
of tests, implemented in datapipe.store.tests.abstract.AbstractBaseStoreTests.
This is a pytest compatible test class. In order to use this set of tests you
need to:
- Create
TestYourStoreclass in tests of your module which inherits fromAbstractBaseStoreTests - Implement
store_makerfixture which returns a function that creates your table store given a specific schema
Example:
import pytest
from datapipe.store.redis import RedisStore
from datapipe.store.tests.abstract import AbstractBaseStoreTests
from datapipe.types import DataSchema
class TestRedisStore(AbstractBaseStoreTests):
@pytest.fixture
def store_maker(self):
def make_redis_store(data_schema: DataSchema):
return RedisStore(
connection="redis://localhost",
name="test",
data_sql_schema=data_schema,
)
return make_redis_store
This will instantiate a suite of common tests for your store.
Migration from v0.13 to v0.14
DatatableTansform can become BatchTransform
Previously, if you had to do whole table transformation, you had to use
DatatableTransform. Now you can substitute it with BatchTransform which has
empty transform_keys.
Before:
# Updates global count of input lines
def count(
ds: DataStore,
input_dts: List[DataTable],
output_dts: List[DataTable],
kwargs: Dict,
run_config: Optional[RunConfig] = None,
) -> None:
assert len(input_dts) == 1
assert len(output_dts) == 1
input_dt = input_dts[0]
output_dt = output_dts[0]
output_dt.store_chunk(
pd.DataFrame(
{"result_id": [0], "count": [len(input_dt.meta_table.get_existing_idx())]}
)
)
# ...
DatatableTransform(
count,
inputs=["input"],
outputs=["result"],
)
After:
# Updates global count of input lines
def count(
input_df: pd.DataFrame,
) -> pd.DataFrame:
return pd.DataFrame({"result_id": [0], "count": [len(input_df)]})
# ...
BatchTransform(
count,
inputs=["input"],
outputs=["result"],
# Important, we have to specify empty set in order for transformation to operate on
# the whole input at once
transform_keys=[],
)
SQLAlchemy tables can be used directly without duplication in Catalog
Starting v0.14 SQLA table can be provided directly into inputs= or
outputs= parameters without duplicating entry in Catalog.
Note, that in order for datapipe db create-all to work, we should use the same
SQLA for declarative base and in datapipe.
Example:
class Base(DeclarativeBase):
pass
class Input(Base):
__tablename__ = "input"
group_id: Mapped[int] = mapped_column(primary_key=True)
item_id: Mapped[int] = mapped_column(primary_key=True)
class Output(Base):
__tablename__ = "output"
group_id: Mapped[int] = mapped_column(primary_key=True)
count: Mapped[int]
# ...
pipeline = Pipeline(
[
BatchGenerate(
generate_data,
outputs=[Input],
),
DatatableBatchTransform(
count_tbl,
inputs=[Input],
outputs=[Output],
),
]
)
# Note! `sqla_metadata` is used from SQLAlchemy DeclarativeBase
dbconn = DBConn("sqlite+pysqlite3:///db.sqlite", sqla_metadata=Base.metadata)
ds = DataStore(dbconn)
app = DatapipeApp(ds=ds, catalog=Catalog({}), pipeline=pipeline)
Table can be provided directly without Catalog
Similar to usage pattern of SQLA tables, it is also possible to pass
datapipe.compute.Table instance directly without registering in catalog.
from datapipe.compute import Table
from datapipe.store.filedir import PILFile, TableStoreFiledir
from datapipe.step.batch_transform import BatchTransform
from datapipe.step.update_external_table import UpdateExternalTable
input_images_tbl = Table(
name="input_images",
store=TableStoreFiledir("input/{id}.jpeg", PILFile("jpg")),
)
preprocessed_images_tbl = Table(
name="preprocessed_images",
store=TableStoreFiledir("output/{id}.png", PILFile("png")),
)
# ...
pipeline = Pipeline(
[
UpdateExternalTable(output=input_images_tbl),
BatchTransform(
batch_preprocess_images,
inputs=[input_images_tbl],
outputs=[preprocessed_images_tbl],
chunk_size=100,
),
]
)